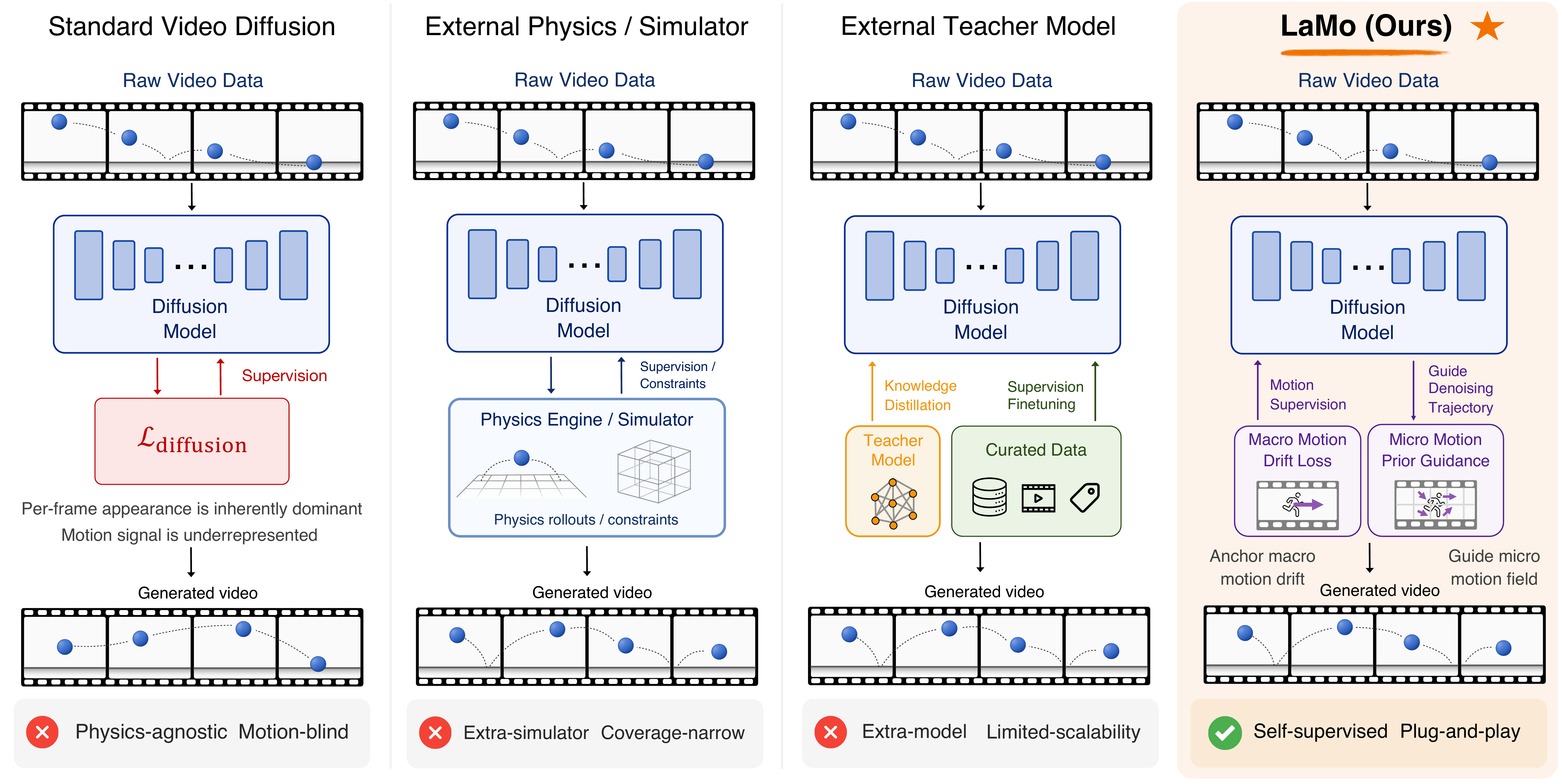
Modern video generators produce visually compelling clips but still
struggle with physical and motion consistency, limiting their use as
reliable world simulators. Existing remedies often rely on external
simulators, teacher models, or curated physics-focused data. We
explore a complementary self-supervised direction: extracting motion
cues from the unlabeled videos already used to train video diffusion
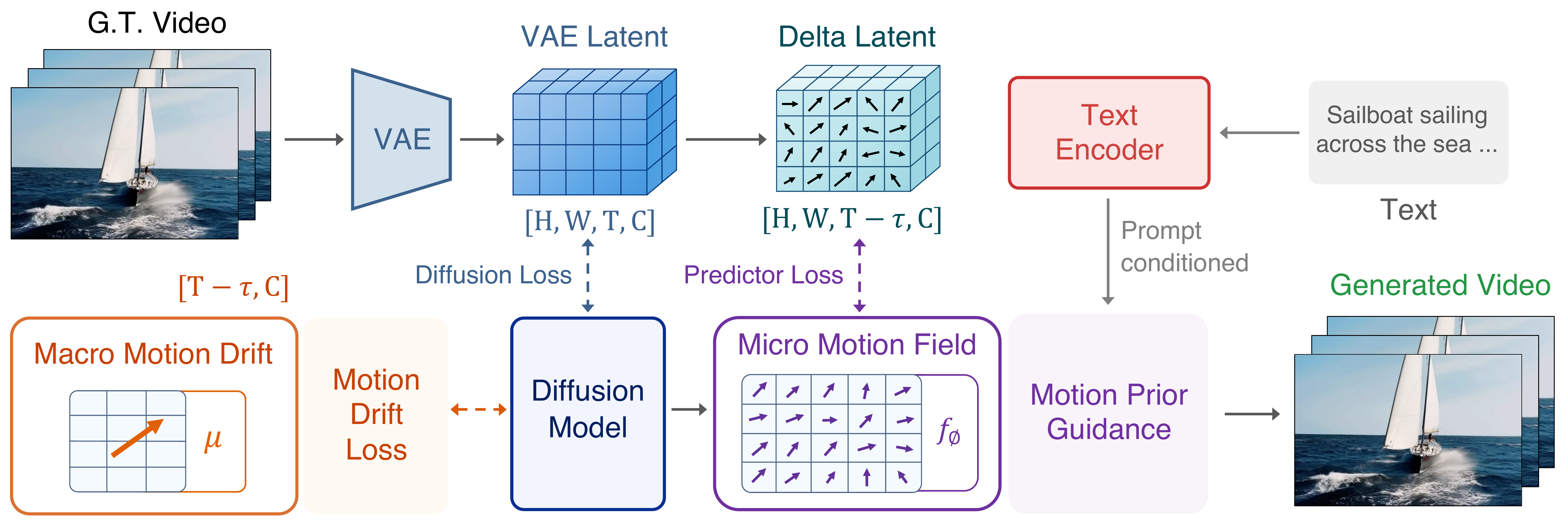
models. We propose LaMo, which formulates a latent motion prior over
frame-to-frame latent changes conditioned on the current latent and
prompt. This prior is exposed through two lightweight readouts: a
macro motion drift used during training as a Motion Drift Loss, and a
learned micro motion field used during sampling as Motion Prior
Guidance. Both components are plug-and-play with existing video
diffusion backbones, requiring no architectural or I/O changes. On
VideoPhy and VideoPhy2, LaMo improves CogVideoX backbones and
outperforms recent physics-aware baselines that use external
supervision. On VBench, it preserves overall generation quality while
improving motion-related dimensions. These results suggest that
unlabeled video contains useful motion supervision for improving
physical fidelity in modern video diffusion models.